Web Application Optimization: Why Most Advice Is Wrong

Most of the advice you run into regarding web application optimization is not only wrong, it’s what I call catastrophically wrong, meaning that it:
- leads you to waste time on optimizations that have negligible impact on actual performance
- leads to making some decisions that actually worsen performance
- completely disregards the performance optimizations that actually do matter
That’s a big claim, and I will back it up.
Before we begin, we need a clear definition of performance for a web application. Only with a good definition of performance in hand can we begin to discuss web application optimization, what’s wrong with so much of the existing advice out there, and what the right advice would look like.
So here it is:
Performance, for a web application, means efficient use of scarce resources over the lifetime of a typical user session.
It’s that second half – which I’ve italicized – which is why most of the advice out there is misguided.
- Web Sites vs Web Applications
- DataGrids, Trees, ComboBoxes: intelligent caching and intelligent use of client-side operation
- Validation: the unsung hero of optimization
- Powerful, Configurable, Flexible UI
- Multi-Record Editing
- Misconceptions & Misunderstandings
- Conclusion
- About the Author
Web Sites vs Web Applications
To see why the standard advice is misguided, we need to think about what the term web application means as compared to web site. We can consider a continuum from websites to web applications, which would look like this:
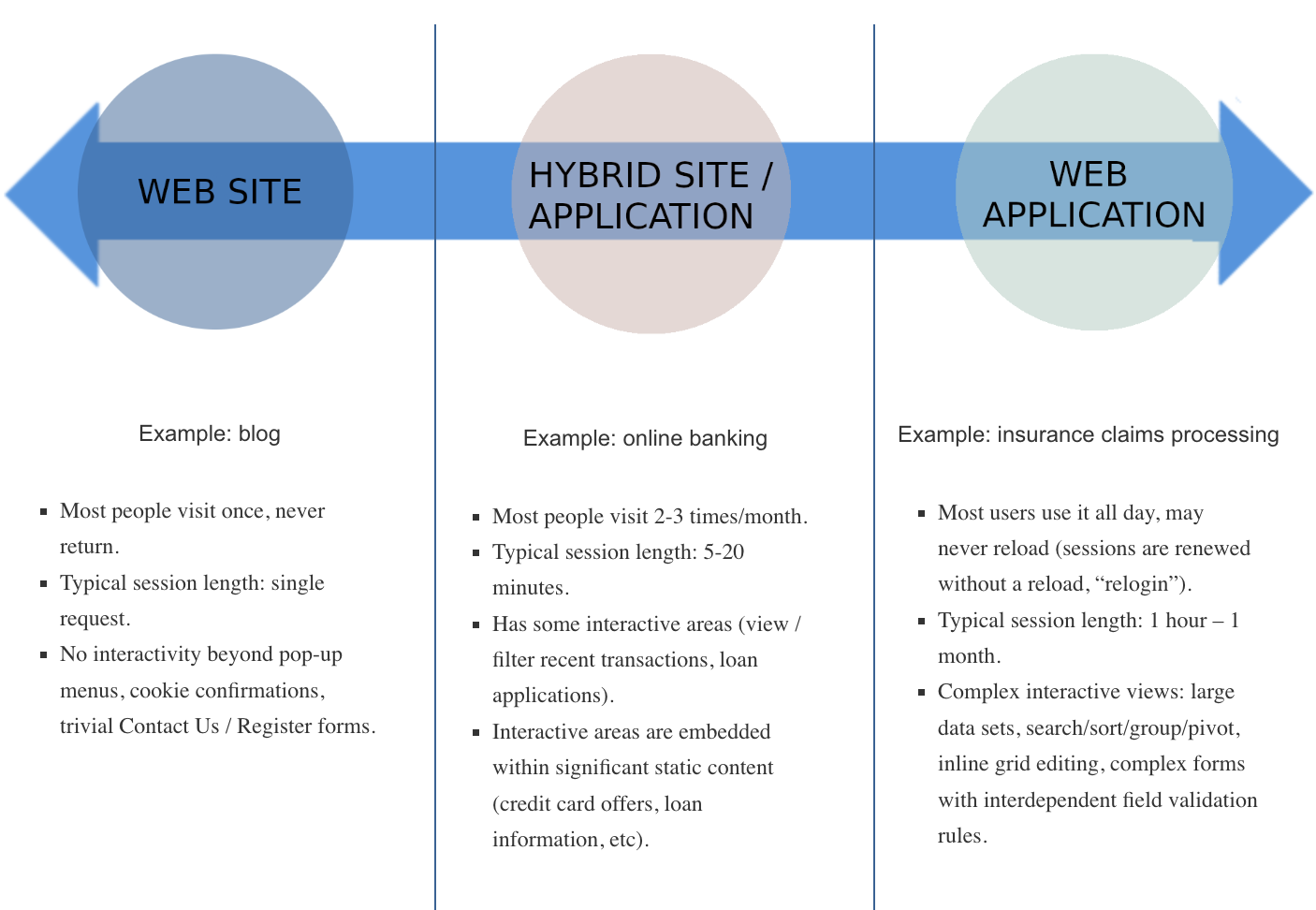



When you consider the right end of this spectrum, you may already be realizing what is wrong about the most common optimization advice.
Almost all web optimization advice is maniacally focused on reducing initial page load time: minifying JavaScript & HTML, using fonts or SVGs or dataURLs as icons, using short file names for images, waterfall analysis of time-to-first-render, and so on.
These techniques only apply to what happens for the first few seconds as an application is loading.
Here we have a category of applications that are used continuously for hours, days, even weeks without ever reloading. That means, all of the classic optimization techniques only apply to <0.1% of the session.
For true web applications, the classic web optimization techniques only apply to <0.1% of the session.
What about the other 99.9%+?
Reducing after-load requests: the key to web application optimization
If you can eliminate server requests by handling more operations inside the browser, you both provide an instant response to the user and reduce server load.
While server-side optimization is also important, there is no server-side optimization that can ever compare to entirely eliminating a request: you could make the server 10,000 times more efficient and it’s still better if it never had to handle the request at all.
When focusing on eliminating server requests, which are the most important to focus on? We can break down the requests that a web application makes into 3 categories:
Type 1: requests for cacheable, static resources like images and JavaScript files, which almost entirely occur mostly during page load. In this context, these are not even worth looking at, except to make sure they are cacheable and there isn’t something egregious like a 1GB .bmp file used as a background image
Type 2: requests that require some server processing
Type 3: requests that hit a database of some kind, that is, shared, read/write storage (doesn’t have to be SQL).
To optimize a web application, we need to look at the Type 2 and Type 3 requests. We’ll approach this with 3 main techniques:
1. Smarter Grids: intelligent caching, adaptive client-side operations, smart cache updates: often, >90% of grid-related data requests can be eliminated.
2. Validation: single-source validation, cache-aware validation, and split validation can eliminate many, many unnecessary validation requests, especially the expensive ones where the server needs to make database requests to perform the validation.
3. Configurability: features such as “saved search” can make a huge performance impact, for subtle reasons that we’ll explain.
In addition to these 3, there is a special fourth optimization technique: developer productivity. Productivity is rightly considered an optimization in its own right, since, if you save time during implementation, you may actually have time for performance analysis and optimization. Many of the techniques we’ll discuss both improve performance and improve developer productivity, and we’ll point out when that’s the case.
Let’s get started.
DataGrids, Trees, ComboBoxes: intelligent caching and intelligent use of client-side operation
DataGrids are at the core of most enterprise applications, and they are the components that most obviously make the most expensive requests, so we’ll start here.
Note that, when discussing optimizations in this area, I mostly just refer to “grids”. However, these optimizations are far broader than what is normally thought of as a “grid”. Specifically, many components that are not called “grids” really are grids. For example:
- a tree is just another type of grid (this is especially obvious if it’s a multi-column tree)
- a combobox, select item or other “drop-down” is just a grid attached to an input field (again, more obvious if the drop-down is multi-column)
- a menu is just a grid. This is especially obvious if it’s a data-driven menu, where some or all of the menu items come dynamically from stored data
- a tiled view is another type of grid. Especially clear if there’s a searching and sorting interface
- a repeating form (multiple identical forms for editing similar records) is another grid
In general, any repeating UI that is attached to a set of similar records is .. you guessed it .. a grid. For simplicity, in this article, I will usually just refer to “grids”, however, bear in mind, I mean all of the above cases, and any other cases of repeating UI attached to a list of data. As far as web application optimization, the techniques and concerns are basically the same.
1. “Adaptive” Filter & Sort
Among the grids that are capable of data paging at all, most operate in one of two modes: either you load all the data up front and the component can do in-browser searches and sorts, or you use data paging and the server is expected to do all of the work.
Our SmartClient components implement something better, which we call Adaptive Filtering and Adaptive Sorting. It means that, if the data set happens to be small enough to be completely loaded, our components automatically & transparently switch over to using local filtering and local sorting, then automatically & transparently switch back to server-based filtering and sorting as needed.
This is not easy to get right – consider a user typing into a dynamic search box: after typing 3 letters (“box”) there are too many matches, but after a 4th letter (“boxe”) now all matches are loaded. If the user types a 5th and 6th letter (“boxed “), you do the filtering locally. But if they backspace over the last three letters of their search string, you need to go back to the server. You also need to go back to the server if they change some other criterion in such a way that the overall criteria is no longer more restrictive than it was at the moment you acquired a complete cache of matching records.
It’s a complicated feature, and we have dozens of automated tests ensuring that it is exactly right in all cases, but, wow, this feature is worth it.
There are two reasons this is so valuable:
- while data paging is a must for reasons explained further on, most of the time, end users are working with much smaller data sets. I have seen just this feature alone eliminate 90% of the requests that were originating from a given screen; I don’t think I’ve ever seen a searchable grid where the impact was less than a 50% reduction in requests.
- small numbers of matching records do not mean that the DB did less work. That’s so important it needs repeating: small numbers of matching records do not mean that the DB did less work. In order to return your 50 matching records, the DB might have consulted thousands, tens of thousands or millions of records. It’s counterintuitive, but it is more often the smaller result sets that correlate with the DB doing lots of hard work. For this reason, eliminating requests that further refine result sets – say reducing from 75 down to 10 – has an enormous impact on database load.
For example, if your end user does a query that returns 50 matching records out of several million, and then they hit sort – right there, that’s a 50% reduction in DB load if that sort is performed locally due to Adaptive Sort.
Similarly, if they typed in a search string, got 50 matching records, and then typed another couple of letters: that’s a tripling of application speed if those last two letters did not result in server requests.
Furthermore, in each of these cases, the end user didn’t have to wait. The local filter or sort returned essentially instantaneously, which is a huge boost to productivity.
To be frank, even though I was the architect of this feature, I didn’t realize the impact that it would have. I had to see the before & after Dynatrace output of DB load before I realized that Adaptive Filtering & Sort was preferentially eliminating the most expensive requests.
Arguably the best thing about this feature is that it’s just on by default in SmartClient. You don’t have to do anything – it just works. When we rolled it out, all of our customers’ apps were upgraded at once.
2. Use incremental rendering & data paging in grids, trees & drop-downs, always, and especially during development
Incremental rendering means rendering only part of the dataset – just rows that have been loaded, for example – and rendering the rest on demand (while scrolling, for example).
Most “lightweight” components, such as react-table, tout the fact that they can render 2000 records worth of data very quickly – just blot out a giant HTML table for all the data, all at once, then you can scroll around freely, since it’s all rendered in advance. Some, like agGrid, offer client-side filtering and sort, again, only if you load all data in advance.
This is worse than useless.
The fact that features vanish once you hit a certain data threshold means you are encouraged to try to load enough data to stay under that threshold – perhaps thousands of rows – even though the end user is likely only viewing the first 30 or so before they either find what they need or change the criteria or sort.
You end up burying the DB to try to compensate for these components’ limitations.
What is particularly problematic here is that these problems are often discovered late in the development cycle: the developers have been working with small sample datasets the whole time, and no one has looked at what happens with real data volume. This can become a catastrophe in multiple ways:
- demos have been given showing features that aren’t actually available for larger datasets, and now that those features can’t be used, there are gaps in the product’s capabilities
- UI logic has been written that inadvertently relied on all records being loaded. When the system is switched over to use data paging, suddenly there are several bugs. Basic systems, such as the way that selected records are tracked, have to be reworked from the ground up
- entirely new data services need to be added to handle cases that were previously handled in-browser
- for existing services, developers scramble to add server-side filtering, sorting and data paging features, which is non-trivial (hint: if you expect your ORM system “just handles” data paging, it won’t, at least, not efficiently, not for non-trivial queries)
I’ve seen this particular type of disaster happen so many times, that I can tell you what happens next: somebody suggests the idea of switching grids into “local mode” only when the data is small enough. This almost works, only:
- the end users are baffled by grid features that are sometimes there and sometimes not
- client-side vs server-side filtering and sorting are similar, but not exactly the same, so end users try to share instructions or even shared searches, but those don’t work for other users
- there are weird edge cases like: if you remove some filter criteria, the grid needs to switch from “local mode” to “server mode”, so the grid needs to be destroyed and re-created, which then loses session information like scroll position, unsaved edits, list of selected records..
In the end, the temptation is just too strong: the developers say: if we just load all the rows every time, we don’t have to deal with all these issues, and we can ship now and somehow fix this in 2.0.
So the application ships that way, and the performance is awful, and usually never really fixed.
So, when considering UI components like grids, trees and drop-downs:
- the UI components should treat data paging and incremental rendering as the default. Having all data locally should be a special case, not the norm. It’s a big red flag if a component treats “all data is local” as the default case
- completely ignore any demos that use local data, and only consider those features to be “real” if you see a demo that shows them working with data paging
- make sure your developers are working with large sample data sets and have data paging enabled in development. If you don’t do this, there will be bugs found late in the development cycle
In sum: treat data paging as a baseline requirement, and select technology accordingly, or you will end up shipping something that is either crippled, or slow, or both at once.
3. Automatic Cache Updates
It’s a very common experience: you select a record from a grid, edit it in a form, save it and return to the grid, and you see the grid reload, because you just changed a record.
It would be far more efficient to just update the grid’s cache in place, but, it’s not necessarily that easy: what if the record has changed such that it should no longer be visible in that grid, because it doesn’t match the criteria for that grid anymore? What if its sort position changed?
Not only is that opportunity to eliminate a request missed, but, often, because data might be stale, other components within the same application perform additional unnecessary requests. For example, after finishing editing in the grid, the end user might return to another screen where the same records from the grid were shown in a comboBox. If those, too, are stale, that is reported as a bug, and the typical developer just forces the comboBox to do a fresh fetch each time.
The result is dozens or even hundreds of unnecessary “cache refresh” requests over a typical session.
The solution is easy enough to state:
- all components that can fetch data have a notion of the “type” of record they are dealing with – they are connected to a central “DataSource” for those records
- when changes are made, the DataSource broadcasts information about the change
- all components that have caches know how to update them in place – they know what criteria & sorting rules were used to load their data, and they can apply those criteria & sorting rules to the updated record to see if it should remain in cache, or shift position
- critically, the criteria and sort applied on the client works exactly the same as if the same criteria and sort had been used in a server fetch. Otherwise the cache update may fail, leaving records around that should be eliminated, or eliminating records that the user would still expect to see
This is an approach that is both a direct optimization and indirectly optimizes the application by reducing coding effort, leaving more time for performance analysis.
Once you’ve got this system in place, you basically no longer have to think about possibilities for stale data – it’s just handled for you.
4. Advanced Criteria: a Cross-Cutting Concern
Once you have Adaptive Filtering and Automatic Cache Updates, you need your client-side filtering system to be very, very powerful and flexible. Why? Because, if the client system can’t closely match server filtering, you have to turn client filtering off, and only rely on server filtering, which means a lot more Type III (database) requests.
For this reason, SmartClient supports arbitrarily deeply nested criteria (as many ands and ors as you like) and a full range of search operators (the usuals like greater than but also things like relative date ranges (with last six months, for example) and the equivalent of SQL “LIKE” patterns). The set of operators is also customizable & extensible, so that you can deal with quirky server filtering and still have client filtering match.
Also important are rules like: client-side filtering is impossible for this particular field, so if criteria changes for this field, we need to ask the server to do filtering. But for any other criteria changes, we can do it locally and offload the server.
Advanced criteria support is also critical for cache updates. To incrementally update a client-side cache, you have to be able to know whether the newly added or newly updated record matches the criteria applied to the overall dataset. If it does, you insert it into the cache, if it doesn’t, you drop it. To make this decision, you will again need a client-side criteria system that is an exact match for the server’s criteria system; otherwise, you have to drop the entire cache and reload (a very expensive Type III request).
To achieve these and other web application optimizations, you need a deep, sophisticated client-side filtering system, which covers a broad range of operators and also allows arbitrarily nested criteria.
Validation: the unsung hero of optimization

Validation may seem a strange place to go looking for optimizations. It’s just checking formats and ranges, right?
The fact is, the more complex your web application becomes, the more you run into validation rules that result in Type II or Type III requests: many validators require checking that related records exist, or that related records are in a specific state, or that a field value is unique amongst all records.
When these validations are performed spuriously or redundantly, they can absolutely hammer your server.
When you catch validation errors early, in the browser, you can avoid server requests. The more sophisticated your validation system becomes, the more requests can be eliminated.
1. Single-Source Validation: consistent, declarative validation across client & server
Most application developers only write the server validation logic, because that’s all that is required for application correctness.
Further, there are often separate server and client teams, and client vs server validators are frequently written in different programming languages, so coordinating to make client validation perfectly match server validation can be difficult.
Because of all of this, often, client-side validators simply aren’t written at all, which leaves a big opportunity for web application optimization untapped – client validation can eliminate thousands of expensive Type II & Type III requests within a single user’s all-day session.
The solution is simple: single-source declarative validation. This means that you declare your validation rules in a format that is accessible to both server and client logic, and the same rule is executed in both contexts, automatically.
To do this, you need a system that spans client and server. There is a “received wisdom” in the industry that you can just pick your client-side UI library and your server-side libraries separately, and they just connect via REST, and you’re all set. When it comes to web application optimization, this is extremely naive: most major web application optimizations involve cross-cutting concerns, where both the client and server teams need to be involved.
Note that I am not asserting that you absolutely must use our SmartClient server and client technologies – like everything discussed here, these are architectural optimizations that can be achieved with any technology, given enough time. In particular, SmartClient’s validator declarations can be expressed in JSON, so, any server-side system could generate the client-side definitions based on some proprietary server-side definitions, and then SmartClient’s client-side system could read those. The same is true with using SmartClient’s server framework with another UI technology.
As an example of mixing and matching, we had a customer that was building a special embedded server for miniaturized network hardware (think mesh networks). For speed and compactness, the server was implemented in raw C (not even C++). They were able to deliver an extremely rich SmartClient-based UI for this tiny device. For part of it, they had a system that could output either C code or SmartClient validator definitions from validators declared in XML Schema. It worked beautifully, and the device and its web UI were extremely rich and efficient.
2. Rich Validator Library with Conditional Validators
Having a single-source declaration of validation rules is key, but, if the built-in declarative validators only cover scenarios like “number must be greater than 5” you are still going to have a lot of trips to the server for more complicated rules.
Basically, the richer your library of declarative validators, the more likely it is that a given validation scenario has a declarative solution with both client- and server-side enforcement, and so the more likely you can have client-side validation logic that avoids Type II & Type III requests.
For this reason, SmartClient’s validation library is extremely rich, and further, supports conditional validation. That is, you can say that a given validation rule only applies when a certain condition is true.
For example, you can easily express things like: ship date cannot be changed if the Order.status is already shipped.
This again relies on advanced criteria, and on those advanced criteria being in a standard format that both the client- and server-side systems can execute. Once you have that, you can express powerful validation rules in a very elegant, declarative fashion (JSON or XML). For example:
<field name=”quantity”>
<editWhen fieldName=”Order.status” operator=”notEquals” value=”Shipped”/>
A rich validation system is another example of something that is both a direct optimization (less server trips due to errors caught by browser logic) and an indirect optimization, in that it saves a lot of coding effort.
3. Split Validation
Just because you can declare validation rules as criteria, that doesn’t mean that you are limited to only expressing validation rules with declarative criteria. You aren’t.
In fact, one of the most powerful optimization techniques is split validation: if you have a complicated rule, and the whole thing can’t be expressed declaratively as criteria, express it partially in criteria, then express the rest of the rule with custom server logic.
The part that is expressed as criteria will be understood by the browser-side system, and will stop unnecessary requests. Then, on the server, the full rule is applied, ensuring enforcement. Here again, I have seen split validation reduce server load so drastically that even end users noticed the effect.
4. Cache-aware validators
A “cache-aware validator” is a validator that is aware of client-side caches and can inspect them in order to potentially avoid expensive server requests.
The best example here is the common “isUnique” validator, which, at the simplest level, can check whether a field value is unique among records of a given type.
This humble-seeming validator is used all the time to check for collisions when users are naming things: projects, cases, estimates, articles, whatever. It’s also used for data consistency purposes, to detect duplicate customers, suppliers, partners, etc.
To illustrate the importance of this, in one large banking customer of ours, years ago, DB performance profiling revealed that 3 different queries related to uniqueness were actually a huge proportion of DB load – more than 30%.
We realized there was an opportunity to make the validator smarter, if it was cache aware. When you are dealing with large datasets which are only partially loaded, you can’t do an “isUnique” check purely on the client, because there might be a collision in data that isn’t loaded. But this doesn’t stop you from implementing this critical web application optimization:
- if there is a collision in local cache, signal an immediate client-side failure (server is never contacted)
- If the local cache happens to be both entirely complete and quite fresh, the validator passes client-side, allowing other client-side validations to be done (which may also prevent an unnecessary server trip, if they fail in-browser) to proceed.
Seemingly simple, but extremely powerful. In the particular app we were looking at, we found that this optimization produced a ~70% reduction in server-side “isUnique” checks, which was a huge boost to overall performance.
We rolled this improvement into SmartClient as a default behavior for the built-in “isUnique” validator, and now, all of our customers get that benefit. We’ve added other “cache-aware” validators as well – it’s a subtle but enormous web application optimization.
5. Standard Validation Protocol – for any type of Object
To avoid unnecessary server trips for validation, you need a validation system that will do smart things like checking all client-side conditions, including validations that are sometimes resolvable client-side but sometimes server-side, before attempting a server request. And, that validation system must be able to request that multiple fields at once are validated on the server, in a single request. This implies a whole standardized protocol for contacting the server, conveying data, returning errors, etc.
Still think you can pick your client and server technologies separately, and just have the React UI guys talk to the Spring Boot server guys and everything will be great? Obviously not. This is a huge area of web application optimization, which can make a night-and-day difference in your application’s performance, scalability, responsiveness and end-user productivity.
The only way to achieve these benefits is a coordinated dialog between client and server teams. Built correctly, a true client & server validation system means that all of the optimizations above, which might seem difficult to apply in an individual screen, instead just happen, without any extra effort on an individual screen.
This is another instance of an optimization that is both strictly a performance optimization and optimizes your app by reducing development effort.
Powerful, Configurable, Flexible UI

There is a kind of “received wisdom” in the industry that highly configurable applications are necessarily slower, because they have to retrieve the configuration information from some database, and then they need a bunch of switching logic to render the view that the user has configured, so that’s slower.
This “received wisdom” is dead wrong, as we will demonstrate.
Perhaps even more important: never underestimate your end users. They know their job far more intimately than you do; as a software engineer or even product manager, you are exposed only to the most pressing concerns of the moment.
You think you understand the design of a particular screen very well, because you designed it or you coded it? No. Your end users know “your” screen far better than you do, because they have figured out the fastest way to use it to do their job, and usually, that isn’t the way you thought it would be used.
When it comes to web application optimization, the fastest, most scalable applications are the ones that have configurability baked in, where end users can configure the application to match their exact usage pattern, even as that usage pattern changes over time.
UI configurability has to be considered a baseline requirement in web application optimization. Configurability enhances both performance and productivity.
Let’s look at some specific examples.
1. Saved Search
This is a subtle one. Saved Search is just a productivity feature, not an optimization, right?
We rolled out a saved search feature at one of our customers and within days the end users were saying wow, what did you do, everything is a lot faster? But in this particular release, we hadn’t intended to roll out web application optimizations. This release was mostly just new features, including saved search.
It was the DBA who finally figured it out: when you arrive at most screens in an application, there is a default search. For example, in personal banking, the default search might show recent transactions. In an issue tracker, the default search might be all open issues for your team.
Because of the pervasive saved search feature we had added, users were now configuring their default search, and replacing that default search with something more relevant to them. In general, those user-specific searches were much lower data volume, made better use of indexes, and hence lowered the database load by enough that even users of other applications were noticing.
Further, before the introduction of the Saved Search feature, most users had a habit of arriving at the default view and then changing it to match what they actually needed. So consider a user doing this:
- see default view (1st unnecessary request)
- change sort (2nd unnecessary request)
- add one criterion (3rd unnecessary request)
- add second criterion (view is now what user needs)
Saved Search – seemingly a convenience feature rather than an optimization – gives you a 4x performance boost in this common situation.
If that seems like a surprisingly large optimization to assign to Saved Search, realize that it’s actually even larger: sophisticated users need to switch between different views of data, and every time they do that, if there is no “saved search” feature, they do so by incrementally changing the search until it matches what they want. So Saved Search not only reduces unnecessary requests when users arrive at a screen, it also reduces requests as end users switch between different views of the data that they need.
Once we fully understood the value of saved search as an optimization, we went to design a saved search feature that could be turned on by default in every single grid, so that in every app ever built with our technology, this particular web application optimization would always be there.
And we did succeed with that – the feature is on by default in all grids, and works by saving searches to the user’s browser (window.localStorage). However, the storage is pluggable, so that you can instead save searches to the server, and also have admins that can create or revise pre-defined searches on-the-fly.
You can see that working here.
2. Other Patterns of End User Configuration
The previous point about Saved Search can be generalized: when you allow your end users to configure your application, they go right to the data they need, they become more productive, and they reduce server load because they are no longer loading data they don’t actually need to look at.
Here are some other examples of configurability that are also optimizations:
Default screen to navigate to after an action
Wherever possible, let users pick the next screen to go to after completing something: at login, when done with a particular process, etc. It’s easy to add something like a dropdown that says “After saving, go to: [list of screens]”. Sophisticated end users will absolutely make use of such a shortcut. You don’t even really need to come up with a way to save their preference across sessions, because with the very long session lengths of true web applications, holding onto that preference for just the session would already be a big boost (but it is better if you can persist it – more on that below).
Saved sets of form values
Imagine “Saved Search” but for forms: with any form in the application, you can save a certain set of values and name it, then re-apply those values whenever you are next using the form. This is easy to build in a general purpose way, so that it can be simply “turned on” for any form in the application.
It’s clearly a productivity feature, but how is it a web application optimization? Well, if filling in the form typically requires navigating two comboBoxes and a pop-up dialog, all of which may require searching through data..
Make your own dashboard
Sophisticated end users are perfectly capable of using a “report builder” or similar interface to create a “dashboard” containing the specific data they need to see – this is especially true of end users who are financial analysts, scientists or the like. If the user isn’t able to create a dashboard directly they are likely to create one indirectly, often in a very inefficient way.
A dashboard builder is, of course, a non-trivial thing to implement. However, some advanced frameworks have this as a built-in capability, easy to turn on for a given screen.
These are examples of configurability that can be applied to almost any application, but the fact is, in general, configurability is very application-specific. The key takeaway here is to understand that configurability increases both productivity and performance.
As far as the perceived drawback of configurability – that you have to save the configuration, load it, apply it, etc – remember that as a developer, you have the option to save configuration in cookies, window.localStorage, and via other mechanisms. Yes, configuration stored via localStorage will be lost if the user switches devices, and that means it’s not necessarily a good choice for something like a user-created dashboard, which the user may well have put some time into. However, for something like a default screen to navigate to after login or after a specific workflow, it may be fine – a minor inconvenience that most users never experience, in exchange for configurability that you get “for free” – zero server load.
3. Rich search, sort, grouping, pivot – never skimp
Many times, I’ve had a customer say something like: “your search capabilities are really powerful, but the UI design calls for a simplified search interface, so we turned the entire default search UI off”
This is a terrible idea. It has led to some of the worst performance problems I’ve ever seen.
Why? Because the designer’s idea of the user’s needs is necessarily incomplete, and the user’s needs change over time.
Having seen so very many projects, I can confidently tell you: the search capabilities you actually need are always, always more than you think at first.
Why limited search is a performance issue
But how is this a performance issue?
Because, when the available search isn’t enough, users still need to get their work done. So they are going to do the search they need to do, somehow, and often the approach they figure out is a performance catastrophe (not to mention the impact on productivity!).
This is one of the key areas in which B2B vs B2C UX design differs, in a way most designers do not fully appreciate: it makes sense to remove advanced search features from a B2C site. It’s rare that a normal consumer would use them, and the removal of unnecessary search features can reduce server load.
But B2B is completely different: your users need to get the search done. If you don’t provide a way to do the search they need, they will come up with a way to do it, because, they have to. It’s their job.
When the available search isn’t enough, users still need to get their work done. Often the approach they figure out is a performance catastrophe.
I have seen lots of clever end user workarounds for underpowered search UIs. For example: one user needed to view certain data side-by-side, and the app didn’t allow it, and also restricted her to one session per browser, so she resorted to installing extra browsers and even VMs to get more sessions, in order to work around an app that just didn’t have the side-by-side view she needed. Her usage was killing the server, but ultimately, the UX team could not come up with a better way of achieving what she wanted to do within the existing UI – her workaround was the best option available, at least until the UI could be re-designed.
Limited search leads to expensive Excel exports
By far the most common performance catastrophe from limited search, which I have seen no less than 5 times, is having users export to Excel and search there instead.
With no better option, users export enormous data sets to Excel; millions of rows in some cases. In each case that I’ve seen this, the analysis that the user needed to do in Excel was not actually complicated; SmartClient’s built-in search features would have let them do it entirely in the browser, or at the least, would have allowed them to refine the search so the export would have been small and not a performance problem.
But instead, with the apps in question, where the UX design had specified a simplified or “streamlined” search interface, the users simply couldn’t do what they needed to do. So of course they went to Excel, and in one case, a particular user’s morning “export” had about a ~30% chance of killing the server (out of memory error), which would interrupt everyone else’s work.
Simplified vs. Sophisticated search: you can have both, with no tradeoffs
To be clear: simplified search interfaces are great. From a UX perspective, you should definitely analyze user behaviors, determine the most common search use cases, and build a UI that allows users to execute those common searches with the minimum number of steps.
At the same time, you should give your users a more flexible & general-purpose search interface. Simplified search and advanced search is not mutually exclusive – we have a SmartClient-based example here showing a straightforward UX that allows both simplified search and advanced search with no compromises. This approach can also be achieved with other UI technologies.
The false optimization of simplified search, and how to correct it
If you provide only a limited search UI, you may well find that your highly optimized default search interface is indeed performing as expected, is very fast and very easy on the server, and then the whole team pats themselves on the back.
Unfortunately, real end users are using something else (whether gigantic exports, dozens of concurrent sessions, or whatever it is) to actually get their work done, and that is killing performance, as well as killing productivity.
Worse, many organizations just don’t communicate effectively across teams. The result is: the design team did a great job! The development team did a great job! The app is slow in production? Must be the DBA’s fault.
You can do better. High-end frameworks usually have excellent built-in search capabilities. When you receive a design that has very limited search capabilities, you can point out that the proposed search interface only handles the known use cases, and advocate for preserving the built-in search capabilities that come with your UI framework. If you are told that’s impossible, you can show them the SmartClient design mentioned above, which allows both simple & advanced search with no tradeoffs.
Also, if slowness is being blamed on the hapless DBA, you can be the voice of clarity, pointing out that end users are working around a bad design.
Multi-Record Editing

Mass Update / Multi-Record Editing
What happens if you need a user to be able to edit multiple records and then save them all at once, as a transaction? Although rare for web sites, this is a common interaction for true web applications.
Frequently, this scenario is handled with server-side storage of unsaved edits, either session-based or DB-based. Often, there’s a rather complicated mechanism of rendering a grid of the original records, with unsaved changes overlaid on top. Because the unsaved changes are stored on the server, validation handling is a continuous chatter between client and server which is extremely inefficient.
We’ve seen multiple customer applications where there was just one screen that involved multi-record editing like this, and even so, it dominated the overall performance of the application.
There’s another way: a client-side component can queue up the changes, display them, validate them (including server contact where necessary), then submit them all as a batch.
When you have this capability, you get two massive web application optimizations:
- enormous numbers of Type II & Type III requests are eliminated, because the unsaved edits are tracked client-side, hence can be checked with client-side validators (including cache-aware validators), which radically reduces expensive server requests
- as discussed previously, you write a lot less code, and especially, a lot less complicated code. Multi-record editing with server-side temporary storage is rather complicated, and if you don’t have to write it, you have a lot more time to actually focus on performance
You may be thinking that this scenario is simply too much complexity to handle with client-side components. However, having first implemented this in 2005 (yes, seriously), we have the interaction very very well handled, with all of the necessary settings and override points to handle a wide variety of variations on the base scenario. There are many, many deployed applications using our approach.
We’ve actually made it so simple that it takes just one property (which we call autoSaveEdits:false) required to turn it on – check it out here. Open your browser tools to look at network traffic – you will see none until the final save.
For applications where this kind of interaction is needed (and it’s not uncommon) this single capability can make the difference between scalable and sluggish.
Tip of the Iceberg
For developers who have been indoctrinated in the school of optimization that is centered on “minimize bytes for initial load”, the set of concepts in this article may come as a bit of a shock.
But this is still just the tip of the iceberg.
If I had the bandwidth and the space to do so, some of the things I would cover would include:
- client-side grouping, pivoting and aggregations: giving users a variety of views of the same data set, without any further server contact
- ultra-flexible grids: why not give the user the ability to preview any long text field under the selected row? Why not let them view related records, on the fly? These flexible views can come with intelligent caching & data reuse, improving productivity and performance at the same time
- client-side SQL-like engines: turn an extensive data analysis session into zero server data requests. This can support far more data volume than you might think
- multi-modal presentation: is it a classic list of rows, a tree, a set of tiles, or a node-and-spokes graph? It’s all of the above, and you can switch on the fly, and the server need not be involved
- multi-containers: is it tabs, an accordion, portlets, a linear layout, a dashboard, floating dockable windows? Again, all of the above, why not allow switching on the fly? When users can take any part of your app and re-mix it, they invent their own best UI, and if they can share it, both productivity and performance skyrocket!
Methodology, not Technology

Even though I have mentioned that our technology implements many of the web application optimizations described above, ultimately, this is not a technology, this is a methodology.
It’s a methodology that can be applied to any project or product, regardless of the technology in use, and it can be taught.
My team has saved countless projects & products. In some, we replaced substantially the entire thing with our technology. In others, we introduced our technology incrementally, in the highest value areas first. In yet others, we never introduced our technology per se; we just applied the patterns.
All of these approaches are solutions that work.
If you are building a true web application, and you want some advice and help reaching the heights that we have reached, reach out. We can give you a quick take for free (already extremely valuable), and go from there.
Misconceptions & Misunderstandings
From here, let’s go into some misconceptions that people have with the above techniques – lots of people don’t immediately understand how to apply these web application optimization techniques, or they believe that their particular web application just doesn’t fit the patterns that I’ve explained.
This is an understandable perception, however, as I will explain, these techniques cover literally everything that humans think about – which is certainly broad enough to cover your web application!
Aren’t all these optimizations just for CRUD? My application has lots of non-CRUD operations
When people are introduced to these optimization techniques, and especially to the idea of a framework that supports such techniques, some people end up with the misperception that these optimizations apply only to a narrow range of CRUD operations. This is incorrect, for two main reasons:
- most “non-CRUD” operations really are CRUD operations. Many people incorrectly conceive of CRUD as a specific set of operations on permanently stored business objects (Orders, Customers and so forth). In fact, CRUD comes from ER (Entity-Relationship) modelling, and applies to any type of object. Objects like UserSessions, Processes, Messages and LogEntries are all entities which can & should be modelled via CRUD.
- even truly non-CRUD operations are usually best modelled via CRUD. This is because non-CRUD operations generally involve input validation, error reporting, structured data responses, and many other requirements that CRUD frameworks handle exceedingly well. Basically, modelling something that is “not CRUD” as CRUD is all upside, and zero downside.
To go deeper, please read my article Why Everything is CRUD – you will come away understanding that substantially all server communication is best modelled via CRUD. And that means that all of the optimization techniques presented here apply, even when dealing with supposedly “non-CRUD” operations.
Why not both? Client-side intelligence and minimum number of bytes downloaded
People sometimes ask: why can’t we have SmartClient’s web application optimization features, but also download a minimum number of bytes on the first ever load?
Usually, this is an ill-posed question. It comes from either:
1. someone who wants to use SmartClient in a very simple, consumer-facing app where each user visits only once, or visits rarely, and with brief sessions. Often, SmartClient’s ability to instantly integrate with data has gotten a developer excited – they made far faster progress with SmartClient than with any “lightweight” technology! However, SmartClient is not the right solution here, and people from Isomorphic will happily tell you so, and guide you to other technologies that are more appropriate.
2. someone who is building a true web application, as covered in this article, but who simply can’t let go of the optimization principles they have learned regarding web sites. They somehow want both: they want a framework that is so light that a casual visitor will barely notice the download, but, is so powerful that a power user has rich functionality.
It’s the #2 crowd that I would like to address here.
First of all, I would readily agree that there are a lot of supposed “tradeoffs” in software design that are not real tradeoffs. As I have covered above, with respect to web application optimization, configurability vs performance is not a real tradeoff: you can get both, and indeed configurability (such as Saved Search) is actually an optimization.
It is also common for developers to assert that an API or UI can either be easy to understand or can be flexible and powerful: it cannot be both at the same time. I don’t agree. I have designed many UIs and many APIs that are simple for novice users, yet flexible & powerful enough to handle extremely advanced use cases.
So when I tell you that there is a real tradeoff in the design of web application optimization – bytes downloaded vs client-side intelligence & optimizations is mutually exclusive – understand that I would love to design a system that handles the entire spectrum of use cases, but it’s just not there.
To understand this, consider designing a fighter jet that is also a good commuter car.
You need to engage enemy jets in a dogfight, and strike a target at night that is defended by radar-guided missile batteries, but also, you need to toodle 10 miles to work each morning, dropping by a drive-through coffee shop.
You can do certain things that work for both use cases – why not have a comfy seat? But then when you go to design an engine that can go Mach 3, you find that, no matter what you do, you are not going to fit that engine into a single lane on a freeway, at least not without toasting the car behind you. You could design foldable wings, but, those wings will not be able to survive the stresses of dogfighting at Mach 2. And so forth.
SmartClient’s architecture is the fighter jet of web applications. SmartClient is unapologetically heavyweight, because, SmartClient can go Mach 3, and the “lightweight” solutions out there simply cannot. In fact, they cannot even get in the ballpark of SmartClient’s performance: with a “lightweight” technology, the page will load quickly, and then the users will wait and wait as they do their actual work.
There have been a number of technologies that claim to be both the “fighter jet” and the “commuter car” at the same time. Without exception, they don’t actually deliver. For example, an old Google GWT demo showed off an impressively low number of bytes for a tabbed pane and a button. But this interface had zero interactivity. If you added an event handler or text input field or anything of the kind, the entire remaining framework code, which had been trimmed off for this specific sample, would be downloaded: it was no longer “lightweight”, at all.
There’s a simple underlying reason for this, that any software engineer can understand: when you design a system well, you re-use as much as you can. In SmartClient, that means that the drop-downs for selects and comboboxes are actually the same as the grid component – data-binding works the same way, you can apply formatters, etc, it’s all the same API.
The grid itself is an instance of the core layout class, so you can insert custom components (like a custom toolbar) into the middle of the grid component.
The form components for standalone use are the same as the ones for inline editing in a grid, and have all the same APIs and customization capabilities. You can literally use the same customized editing controls for inline editing in a grid and in a standalone form.
Similarly, when people use components like SmartClient’s menu or combobox system, they see the same APIs they used to configure grids: formatting configuration, extra columns, icon declarations, the works.
What’s the general principle here?
Minimizing bytes downloaded for a narrow use case is in direct conflict with reuse. This is an inherent conflict, irreducible.
And, as a simple corollary: when you need a robust feature set, SmartClient, which features a huge amount of reuse, is going to be by far smaller than combining a bunch of different components from different vendors, which will necessarily include repeated re-implementations of the same core capabilities, over and over again, all of which need to be downloaded to make a complete application.
If someone could deliver SmartClient’s full feature set in an astonishingly low number of bytes, I would love that. In the meantime: SmartClient outperforms other web application technologies by 30x or more, and this is something that can be easily measured and verified.
If someone is interested in working with us to create a technology that broadens SmartClient’s reach, a way of maximally blending full-power web application optimization with minimum downloads, we would be delighted to do that. There are definitely applications in the middle ground between true web applications and web sites, where such a “blended” technology would be useful.
But if you are trying to create a web application today? Even if you do not use SmartClient per se, the SmartClient architecture is the right one, and by an enormous margin – it’s not close.
Conclusion

I hope I have given you some tools to think about the design and architecture of your application, and how to approach both optimization and implementation.
Although I have referred to SmartClient technology in a number of areas above, again, what is covered in this article is actually a methodology, not a technology per se. This methodology can be applied with any technology, and if this article was not enough of a guide, Isomorphic can help you with it.
If you have any feedback on this article, I would love to hear from you! There is plenty of room to improve on what’s here. The best way to get in touch is to Contact Us.
About the Author
Charles Kendrick has been the head of Isomorphic Software for over 20 years. He is the Chief Architect of SmartClient and Reify. Both products are heavily used and very popular amongst the Fortune 500. He has successfully worked with and coached dozens of teams delivering high performance systems and is a pioneer in the field of web application optimization.