Optimizing Web Applications vs Web Sites
Most of the time, when you read advice about optimizing your web properties, the advice is provided without making a distinction between building a web site vs building a web application.
This assumes that the approach to optimizing a basic web site – for example, a site showing off an artist’s portfolio – is basically the same as that for optimizing a full-blown business web application such as NetSuite.
In reality, while there are some common elements to optimizing these very different web properties, there are also major differences in approach. It’s not just that the priorities are different: some of the common advice actually backfires, making things worse.
Specifically, if you are building a web application and you apply advice oriented toward web sites, this:
- leads you to waste time on optimizations that have negligible impact on actual performance
- leads to making some decisions that actually worsen performance
- leaves no time to implement the performance optimizations that actually do matter
Let’s dig in.
- How Web Applications and Websites differ
- Examples of real Web Applications (it’s not an edge case)
- How Web Applications and Websites differ in terms of optimization
- Type 1 or “static” requests: static, possibly cacheable resource
- Type 2 or “app tier” requests: requests that require authentication, touch session data, or in some other way force the application tier to do work
- Type 3 or “shared DB” requests: access a central, read/write store (basically a database)
- Techniques for Web Application optimization
- True Web Application platforms
- Feedback
How Web Applications and Websites differ
Before we start, we need a clear definition of performance with regard to a web site or a web application. It is:
Performance, for a web application, means efficient use of scarce resources over the lifetime of a typical user session.
It’s that second half – which I’ve italicized – which is why much of the advice out there is misguided.
To see why the standard advice is misguided, we need to think about what the term web application means as compared to web site. We can consider a continuum from websites to web applications, which would look like this:
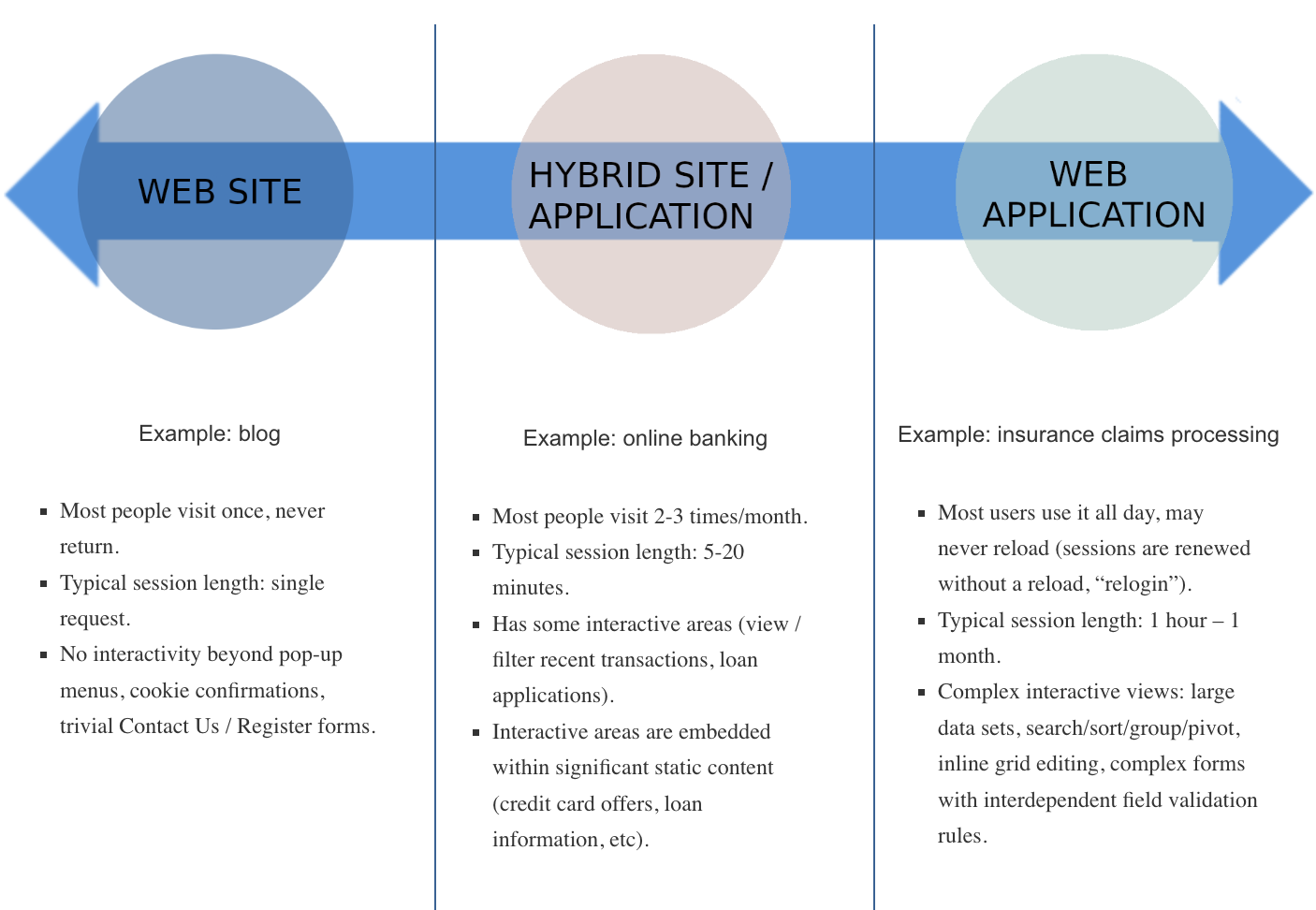



Of course, not everything fits neatly onto this continuum, but it is a valuable analysis tool. Considering the right end of the spectrum, you may already have an idea of what’s wrong with the most common advice.
Let’s consider the case of a web application we’ve built multiple times for some of the world’s biggest insurance carriers: insurance claims processing. This is an app that users continuously interact with, all day, every day, with multiple tabs open processing separate claims concurrently. It contains lots of complex data validation rules and integrates with multiple data streams.
This application basically never reloads. In our diagram above, I refer to session lengths up to “1 month”, but there’s really no upper limit – on several occasions, I’ve seen pages older than a month.
Really, the only thing that limits the page lifetime is upgrades; when a new version of the app is rolled out, users finally need to reload. In fact, often, the maximum page lifetime is limited by operating system reboots!
In this scenario of a page that never reloads, you may wonder about session expiration – doesn’t that require a page reload? No, it does not: when a user goes for lunch or attends a meeting, they come back to a dialog telling them their session expired and to please log in. Once the “relogin” is accomplished, they’ll realize the page does not reload.
Now that we know that there is such a thing as a page that basically never reloads, we can begin to appreciate just how different the approach to web application optimization is going to be.
In particular, all of the common concerns are either gone or recast in a different light:
- Concerns about “lightweight components” that deliver basic functionality in the minimum number of bytes: irrelevant
- Concerns about carefully trimming unused functionality: just give me the kitchen sink, and don’t bother me again!
- Waterfall analysis of initial load: needless beyond determining that everything cacheable is cached for next month’s reload
- Media loading and debates about image codecs, SVG vs. web fonts, and all that: it’s important for web frameworks to support formats maximally, but trimming media bytes will have no measurable impact on performance
The usual concerns are out the window! But is this kind of application actually common?
Examples of real Web Applications (it’s not an edge case)
You may now be thinking, OK, you’ve got a rare, edge-case application where web application optimization is very different, but it’s just a single edge case.
Not so. While applications like these are 1000x less common than ordinary websites, they are not rare.
Let’s take a look at some examples of web applications:
- Drug discovery dashboards: Take a drug candidate, look at all the in vivo & in vitro assays done on it (hepatotoxicity, pharmacokinetics, etc.), compare with in silico / deep learning models, figure out the next drug candidate to synthesize and repeat.
- Securities analysis: Combine past performance, fundamentals, predictions from many sources, and your own proprietary models, along with risk models and your firm’s particular exposure, then act: buy/sell/trade/hedge.
- Logistics/fleet management/warehousing: Track all of your vehicles (land, water, air), their contents, and how they compare to projections of demand, then model possible changes and execute them.
- Chip manufacturing: Rapidly explore massive datasets to find the sweet spot of performance vs. RF interference vs. printed circuit size vs. reliability and other factors. It’s a complex process, especially for communications chips and other mixed analogs and digital devices.
- Real-time trading: “Christmas tree” interfaces continuously receiving market data and doing real-time comparisons with predictive models to guide the next trades.
- Defense: Too many to list. This category overlaps with logistics and deep bidding systems for prime contractors, drone/satellite media management, and many other things.
- Network management/virtualization: live views of networks and their status, multiple performance metrics, ability to set complex alerts, and automate corrective actions.
I could go on at some length, but you get the point: web applications are indeed 1000x less common than websites, but they are also critically important – this is the software that keeps the complex infrastructure of the modern world humming along.
Given the importance of these applications, we need a practice of web application optimization that works well for such apps. And this is what my company, Isomorphic, has focused on for 20 years.
How Web Applications and Websites differ in terms of optimization
Returning to our definition of performance:
Performance, for a web application, means efficient use of scarce resources over the lifetime of a typical user session.
What does web application optimization mean when the session length is as much as one month? The focus completely shifts: now, we are trying to minimize the use of resources after the page has loaded.
But what specific types of requests need to be avoided? We can break them down by type, in increasing order of cost:
Type 1 or “static” requests: static, possibly cacheable resource
It doesn’t matter if you load something like an icon after a page load. It’s cacheable, and unless you’ve botched your caching setup, the resource will never be loaded again (even on the full-page reload coming up next month).
Likewise, things like a user’s profile picture, or a definition from Wikipedia – these are requests where it’s well understood how to scale them basically infinitely.
This is not a “scarce resource”. When it comes to web application optimization, such requests can be basically ignored.
Type 2 or “app tier” requests: requests that require authentication, touch session data, or in some other way force the application tier to do work
Scaling authentication systems is well-understood, but not as trivial as scaling requests for unauthenticated static content.
Further, any request that touches session data causes an access to a data store (DB or memory) that is synced across all servers in the application tier. So here, we’re starting to see requests that matter.
However, the defining trait of a “Type 2” request is that it really only touches data relevant to one user (for example, session data or data about preferences). Such requests can be horizontally scaled: just add more app tier servers, more replicated or segmented databases, use geo-DNS, etc.
Type 3 or “shared DB” requests: access a central, read/write store (basically a database)
This is where to focus. When approaching web application optimization, if you haven’t completely bungled the architecture, and you’ve already solved the easy stuff, the final bottleneck is always, always some kind of shared read/write data store.
To be very clear: we are talking about shared storage that is frequently accessed and frequently written to, and also where it’s important everyone is seeing the latest data. Data stores that are mostly read-only are easy enough to scale, as are data stores that can be written to, but where it’s not very important that people are seeing the very latest (think: social networks).
In all of the types of applications I’ve mentioned above, we are looking at frequent read/write access, and synchronization is important (a securities trader cannot be looking at stale data!).
You can now see how different this is. Classic optimization techniques pretty much focus on Type 1 requests. In web application optimization, those are all but ignored – they don’t matter!
Techniques for Web Application optimization
To deeply understand the approach for web application optimization, you should read my Web Application Optimization article, however, to get a quick idea, the major areas are:
Adaptive client-side operations
While many common data grid components are capable of doing client-side filtering & sorting when all data is loaded up front, there is another level: Adaptive Filtering & Sorting. This technology allows client-side filtering and sorting to take over opportunistically & automatically when a filtered dataset becomes small enough to load locally.
This means that you can handle million-row datasets and still get the maximum possible advantage from client-side processing, providing instant responses to users while simultaneously reducing server load.
Caching & data re-use
Maximum data re-use happens when all components share a common databinding approach: you can use the already-loaded data in a grid to populate a form, or switch to a tiled view of the same data, or the data is used to drive a combobox that allows selecting from values that are already in the dataset.
Ideally, this is all as automatic as it can be, because all of the relevant UI components are connected to a common databinding framework.
Further, a common databinding framework means that when one component saves data, other components can update their caches, in place. This avoids countless “data refresh” requests that shouldn’t be required.
Single-source, declarative validation
Errors that can be caught by browser-side validation avoid unnecessary trips to the server.
Single-source validation means that you declare all your validation rules in one place, and they are automatically enforced both client- and server-side. This avoids the need to implement validators in two places, which usually leads to skipping the implementation of client-side validators.
With single-source validation, there no additional effort to get client-side validation. Also, the more robust the set of available validators, the more trips this saves.
Cache-aware validators & split validation
Cache-aware validators use data caches to avoid unnecessary trips, by, for example, checking for uniqueness of values using a local cache. With a large dataset that is only partially loaded, you can’t do an authoritative uniqueness check on the client. But what you can do is flag values that are definitely not unique, so there is no trip to the server to check.
Similar tricks apply to many kinds of validators, especially the most expensive ones: validators that, if checked server-side, will require the server to consult a database, possibly performing multiple, expensive queries. A common example is relational validators, which need to check fields on related entities (e.g. orderItem.quantity can’t be changed if order.status is “Shipped”). Cache-aware validators are especially good at avoiding these more expensive server validation requests.
“Split validation” is a related technique: you may have something you logically think of as a single validation rule, but there is a way to split into two rules, one of which can be checked client-side. When the client-side portion of the validation rule fails, a server trip is avoided.
Configurability (e.g. Saved Search)
Saved Search and other end-user-configuration capabilities allow users to go directly to the data they need to complete a task.
In the absence of such features, when users arrive at a given screen, they just load the default data. Not only is that an expensive, wasted request, it may take multiple requests before the user is looking at the data they actually need to see.
Then, if they switch tasks, it may again be several more data requests before they are looking at the data that is relevant to their new task.
Saved Search and other configurability features avoid these unnecessary “default” data load operations. Other configurability features that do this include end-user-configurable dashboards/data views, and accelerator menu options (like “Save and go to Next Screen“) that bypass unnecessary steps.
True Web Application platforms
From the preceding discussion, you may have realized something important: if a framework offers the optimizations that matter for a web application, it’s going to be pretty big. It’s going to offer a lot of different data-aware components organized around a common, robust databinding approach. It’s going to have a rich library of search operators, validators, and so forth.
This is not going to be a framework that is suitable for adding a simple flyout menu to an ordinary web page – it’s going to be too large for that.
In fact, there is an inherent conflict between being lightweight enough to use for minor website enhancements vs being powerful enough to provide deep optimization for true web applications.
We can return to our continuum and see this visually, by looking at the range of use cases for our technology (SmartClient) vs the use cases that are targeted by typical web components.
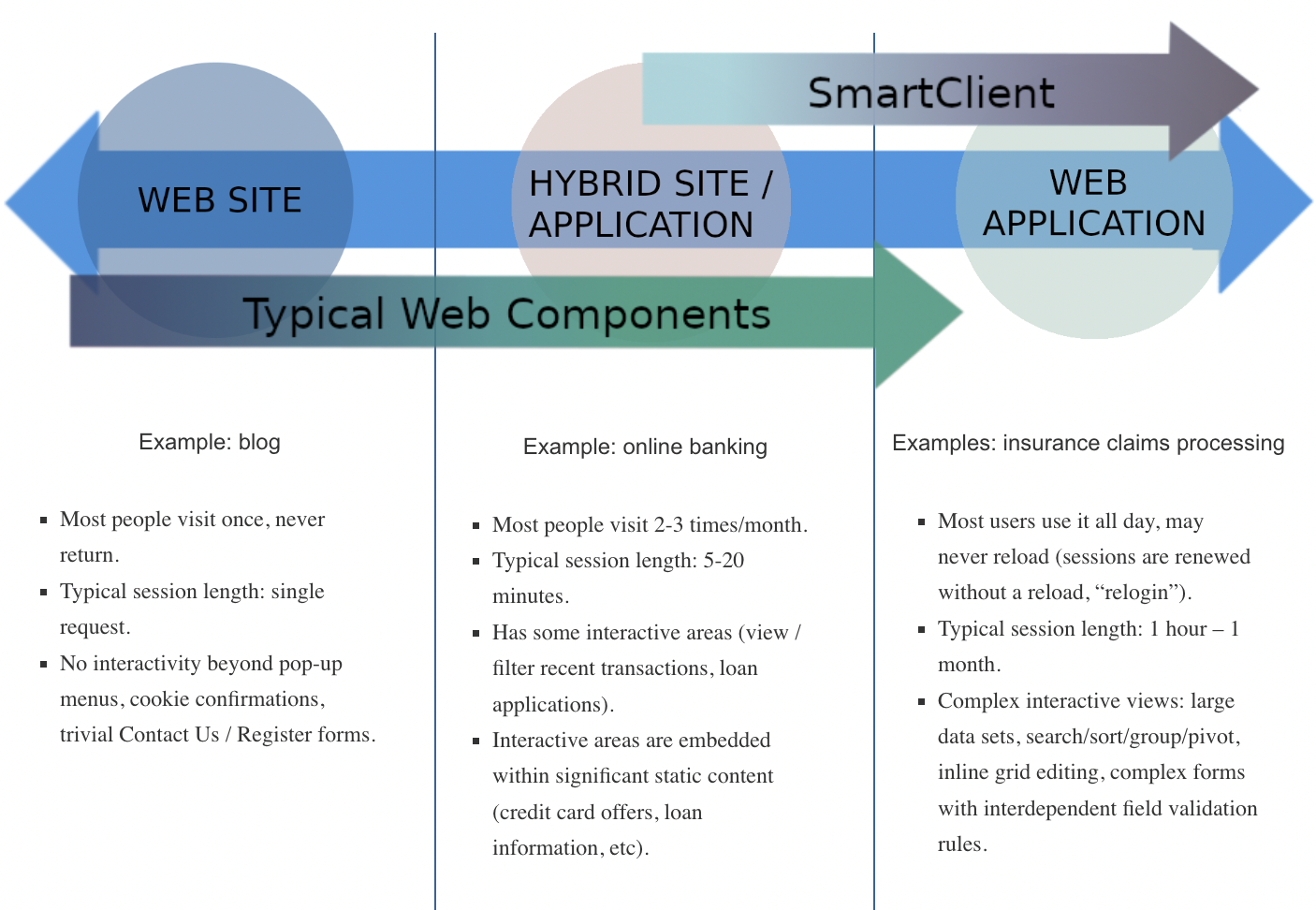


The SmartClient framework is specifically designed for true web applications. By focusing on this use case, SmartClient is able to achieve a level of performance that is simply unreachable for ordinary web components. Our teams are often tasked with replacing existing applications that were built with “lightweight” components, and it’s not unusual for us to achieve a 10x to 30x performance increase, often with a much shorter implementation time.
To be clear, you don’t have to use SmartClient to achieve these optimizations. The advantage with SmartClient is that many of these optimizations are just “built-in” – they happen automatically if you just build your application in the most efficient way.
However, if you have existing applications written in some other technology or you are in a totally different context (maybe not even the web?), the approaches that are built into SmartClient can still be applied.
Feedback
If you have any feedback on this article, I would love to hear from you!
The best way to get in touch is to Contact Us.
About the Author
Charles Kendrick has been the head of Isomorphic Software for over 20 years. He is the Chief Architect of SmartClient and Reify.
Both products are heavily used and very popular amongst the Fortune 500. He has successfully worked with and coached dozens of teams delivering high-performance systems and is a pioneer in the practice of web optimization.



